|
||||||
|

Adding Tensorflow to an existing Android OpenCV application (where OpenCV digitizes image and
provides callback for video frames)
Video demo of the Code working
FIRST: you should read the other option on cloning the code because it explains the code they provide (and you will be using this code here --adding it to YOUR project)
************CODE***********
STEP 1: Unzip the code to a directory
STEP 2: Separately create a new bland ANdroid project and add the OpenCV module to the project (see class materials on help for this)
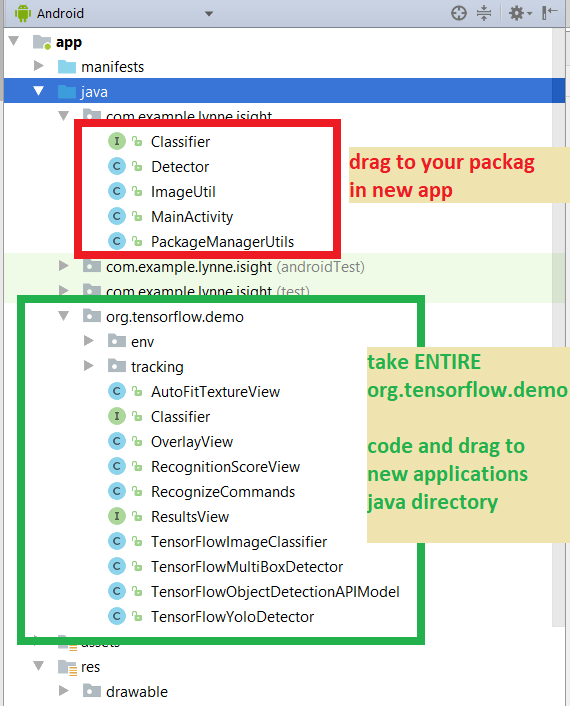
STEP 3: Copy over ALL the java code from the zip directory application to your new application
STEP 3.1) my com.examp.lynne.isight will go to whatever the package name is of YOUR new applicaiton code
STEP 3.2) copy the package code org.tensorflow.demo into your java directory
A quick explanation of the Detector.java code --- this basically is a simplified version of the original code in DetectorActivity in the cloned code (from tensorflow.org's github) --- I simply sets up one of 3 CNNs - TensorFlowObjectDetectionAPIModel OR TensorFlowYoloDetector OR TensorFlowMultiBoxDetector based on the hardcoded class variable called MODE (currently set for TensorFlowObjectDetectionAPIModel.
Then it uses this CNN to run on images that OpenCV captures from the camera.
Various trained models and object list (this is list of objects can detect) are in the assests directory.
Each of the TensorFlow* CNN class represent different CNN's like the TensorFlowObjectDetectionAPIModel uses SSD (single shot detector) algorithm to create the CNN and use it. The TensorFlowYoloDetector uses the Yolo algorithm
Controll of the camera and any image processing can be done by OpenCV. The input to the CNN requires a specially formatted image and is specific to the trained model and will require you to CHANGE THIS CODE for any new models either you create or try to use and this will include: choosing color space, size of input image and how you put the 2D image pixels into a 1D input array for the CNN. Currently this code:
resizes the rgb image to 300x300 for the TensorFlowObjectDetectionAPIModel that uses the ssd trained model in the assets file.
Detector.java EXPLAINED through color coded comments
package com.example.lynne.isight;
import android.app.Activity;
import android.graphics.Bitmap;
import android.graphics.Canvas;
import android.graphics.Color;
import android.graphics.Matrix;
import android.graphics.Paint;
import android.graphics.Rect;
import android.graphics.RectF;
import android.graphics.Typeface;
import android.os.SystemClock;
import android.util.Size;
import android.util.TypedValue;
import android.widget.Toast;
import org.tensorflow.demo.*;
import org.tensorflow.demo.Classifier;
import org.tensorflow.demo.env.BorderedText;
import org.tensorflow.demo.env.ImageUtils;
import org.tensorflow.demo.env.Logger;
import org.tensorflow.demo.tracking.MultiBoxTracker;
import java.io.IOException;
import java.util.LinkedList;
import java.util.List;
import java.util.Random;
/**
* Created by Lynne on 11/7/2017. * Class to assist with creation of a Tensorflow CNN model from a trained model file
* stored in the assets folder * * has 2 main methods of importance:
* * 1) setupDetector * method to setup instance of a Classifier stored in class variable detector depending on the MODE
* value set for this class (for YOLO, MULTIBOX or Object Detection API (uses SSD trained model))
* expects the trained model (.pb file) and the trained labels list (.txt file) to be located
* in the applications assets directory * * 2) processImage(Bitmap) *
* method to process the Image by passing it to the detector (Classifier instance previously setup)
* using as input the imageBitmap AND draws the results -bounding box + label + confidence for recognitions made >threshold
*/
public class Detector {
private static final Logger LOGGER = new Logger();
// Configuration values for the prepackaged multibox model.
private static final int MB_INPUT_SIZE = 224;
private static final int MB_IMAGE_MEAN = 128;
private static final float MB_IMAGE_STD = 128;
private static final String MB_INPUT_NAME = "ResizeBilinear";
private static final String MB_OUTPUT_LOCATIONS_NAME = "output_locations/Reshape";
private static final String MB_OUTPUT_SCORES_NAME = "output_scores/Reshape";
private static final String MB_MODEL_FILE = "file:///android_asset/multibox_model.pb";
private static final String MB_LOCATION_FILE =
"file:///android_asset/multibox_location_priors.txt";
private static final int TF_OD_API_INPUT_SIZE = 300;
private static final String TF_OD_API_MODEL_FILE =
"file:///android_asset/ssd_mobilenet_v1_android_export.pb";
private static final String TF_OD_API_LABELS_FILE = "file:///android_asset/coco_labels_list.txt";
// Configuration values for tiny-yolo-voc. Note that the graph is not included with TensorFlow and
// must be manually placed in the assets/ directory by the user.
// Graphs and models downloaded from http://pjreddie.com/darknet/yolo/ may be converted e.g. via
// DarkFlow (https://github.com/thtrieu/darkflow). Sample command:
// ./flow --model cfg/tiny-yolo-voc.cfg --load bin/tiny-yolo-voc.weights --savepb --verbalise
private static final String YOLO_MODEL_FILE = "file:///android_asset/graph-tiny-yolo-voc.pb";
private static final int YOLO_INPUT_SIZE = 416;
private static final String YOLO_INPUT_NAME = "input";
private static final String YOLO_OUTPUT_NAMES = "output";
private static final int YOLO_BLOCK_SIZE = 32;
// Which detection model to use: by default uses Tensorflow Object Detection API frozen
// checkpoints. Optionally use legacy Multibox (trained using an older version of the API)
// or YOLO.
private enum DetectorMode {
TF_OD_API, MULTIBOX, YOLO;
}
private static final Detector.DetectorMode MODE = Detector.DetectorMode.TF_OD_API;
// Minimum detection confidence to track a detection.
private static final float MINIMUM_CONFIDENCE_TF_OD_API = 0.6f;
private static final float MINIMUM_CONFIDENCE_MULTIBOX = 0.1f;
private static final float MINIMUM_CONFIDENCE_YOLO = 0.25f;
private static final boolean MAINTAIN_ASPECT = MODE == Detector.DetectorMode.YOLO;
private static final Size DESIRED_PREVIEW_SIZE = new Size(640, 480);
private static final boolean SAVE_PREVIEW_BITMAP = false;
private static final float TEXT_SIZE_DIP = 10;
private Integer sensorOrientation;
private org.tensorflow.demo.Classifier detector;
private long lastProcessingTimeMs;
private Bitmap rgbFrameBitmap = null;
private Bitmap croppedBitmap = null;
private Bitmap cropCopyBitmap = null;
private boolean computingDetection = false;
private long timestamp = 0;
private Matrix frameToCropTransform;
private Matrix cropToFrameTransform;
private MultiBoxTracker tracker;
private byte[] luminanceCopy;
private BorderedText borderedText;
int cropSize;
/**
* method to setup instance of a Classifier stored in class variable detector depending on the MODE
* value set for this class (for YOLO, MULTIBOX or Object Detection API (uses SSD trained model))
* expects the trained model (.pb file) and the trained labels list (.txt file) to be located
* in the applications assets directory --see above for hardcoded locations for each type of
* detector
* @param parent_Activity parent Activity that invokes this method as need to be able to
* grab assets folder of application as well as output a toast message to
* Activity in case problems with creating the Detector.
*/
public void setupDetector(Activity parent_Activity){
//
cropSize = TF_OD_API_INPUT_SIZE;
//create Detector as instance of either TensorFlowYoloDetect,
// TensorFlowMultiBoxDetector or TensorFlowObjectDetectionAPIModel
//depending on the MODE set for this class
if (MODE == Detector.DetectorMode.YOLO) {
detector =
TensorFlowYoloDetector.create(
parent_Activity.getAssets(),
YOLO_MODEL_FILE,
YOLO_INPUT_SIZE,
YOLO_INPUT_NAME,
YOLO_OUTPUT_NAMES,
YOLO_BLOCK_SIZE);
cropSize = YOLO_INPUT_SIZE;
} else if (MODE == Detector.DetectorMode.MULTIBOX) {
detector =
TensorFlowMultiBoxDetector.create(
parent_Activity.getAssets(),
MB_MODEL_FILE,
MB_LOCATION_FILE,
MB_IMAGE_MEAN,
MB_IMAGE_STD,
MB_INPUT_NAME,
MB_OUTPUT_LOCATIONS_NAME,
MB_OUTPUT_SCORES_NAME);
cropSize = MB_INPUT_SIZE;
} else {
try { //create TensorFlowObjectDetectionAPIModel CNN (using ssd model file)
detector = TensorFlowObjectDetectionAPIModel.create(
parent_Activity.getAssets(), TF_OD_API_MODEL_FILE, TF_OD_API_LABELS_FILE, TF_OD_API_INPUT_SIZE);
cropSize = TF_OD_API_INPUT_SIZE;
} catch (final IOException e) {
LOGGER.e("Exception initializing classifier!", e);
Toast toast =
Toast.makeText(
parent_Activity.getApplicationContext(), "Classifier could not be initialized", Toast.LENGTH_SHORT);
toast.show();
}
}
// add code to setup the croppedBitmap size as cropSizexcropSize
croppedBitmap = Bitmap.createBitmap(cropSize, cropSize, Bitmap.Config.ARGB_8888);
}
/**
* method to process the Image by passing it to the detector (Classifier instance previously setup)
* using as input the imageBitmap
* @param imageBitmap image want to process
*
* @return Bitmap which is bitmap which has drawn on top rectangles to represent the locations of
* detected objects in the image along with their identity and confidence value
*/
protected Bitmap processImage(Bitmap imageBitmap) {
++timestamp;
final long currTimestamp = timestamp;
//if detector not set up do not process the image
if (this.detector == null)
return imageBitmap;
//LLL- *************************************************************************
//LLL -- add code to do creation of scaled image using Matrix transformation
frameToCropTransform =
ImageUtils.getTransformationMatrix(
imageBitmap.getWidth(), imageBitmap.getHeight(),
cropSize, cropSize,
0, false);
/*frameToCropTransform =
ImageUtils.getTransformationMatrix(
imageBitmap.getWidth(), imageBitmap.getHeight(),
cropSize, cropSize,
0, MAINTAIN_ASPECT);*/
cropToFrameTransform = new Matrix();
frameToCropTransform.invert(cropToFrameTransform);
//now create a canvas from a new bitmap that will be the size of cropSizexcropSize
final Canvas canvas1 = new Canvas(croppedBitmap);
canvas1.drawBitmap(imageBitmap, frameToCropTransform, null); //copy over and scale to get cropSize x cropSize in canvas
// For examining the actual TF input.
if (SAVE_PREVIEW_BITMAP) {
ImageUtils.saveBitmap(croppedBitmap);//saves to "preview.png" NOT NEEDED
}
//END-**********************************************************
//Now pass this to Classifier detector to perform inference (recognition)
LOGGER.i("Preparing image " + currTimestamp + " for detection in bg thread.");
//run in background -- LYNNE TO DO make in background
LOGGER.i("Running detection on image " + currTimestamp);
final long startTime = SystemClock.uptimeMillis();
final List<Classifier.Recognition> results = detector.recognizeImage(croppedBitmap); //RUN CNN on croppedBitmap
lastProcessingTimeMs = SystemClock.uptimeMillis() - startTime;
//Now create a new image where display the image and the results of the recognition
Bitmap newResultsBitmap = Bitmap.createBitmap(imageBitmap);
final Canvas canvas = new Canvas(newResultsBitmap); //grab canvas for drawing associated with the newResultsBitmap
final Paint paint = new Paint();
paint.setStyle(Paint.Style.STROKE);
paint.setStrokeWidth(2.0f);
paint.setTextSize(paint.getTextSize()*2); //double default text size
Random rand = new Random();
float label_x, label_y; //location of where will print the recogntion result label+confidence
//setup thresholds on confidence --anything less and will not draw that recognition result
float minimumConfidence = MINIMUM_CONFIDENCE_TF_OD_API;
switch (MODE) {
case TF_OD_API:
minimumConfidence = MINIMUM_CONFIDENCE_TF_OD_API;
break;
case MULTIBOX:
minimumConfidence = MINIMUM_CONFIDENCE_MULTIBOX;
break;
case YOLO:
minimumConfidence = MINIMUM_CONFIDENCE_YOLO;
break;
}
final List<Classifier.Recognition> mappedRecognitions =
new LinkedList<Classifier.Recognition>();
//dummy paint
paint.setColor(Color.RED);
canvas.drawRect(new RectF(100,100,200,200), paint);
canvas.drawText("dummy",150,150, paint);
//cycle through each recognition result and if confidence > minimumConfidence then draw the location as a rectange and display info
for (final Classifier.Recognition result : results) {
final RectF location = result.getLocation();
if (location != null && result.getConfidence() >= minimumConfidence) {
//setup color of paint randomly
// generate the random integers for r, g and b value
paint.setARGB(255, rand.nextInt(255), rand.nextInt(255), rand.nextInt(255));
//we must scale the original location to correctly resize
//RectF scaledLocation = this.scaleBoundingBox(location, croppedBitmap.getWidth(), croppedBitmap.getHeight(),imageBitmap.getWidth(), imageBitmap.getHeight());
// canvas.drawRect(scaledLocation, paint);
cropToFrameTransform.mapRect(location);
RectF scaledLocation = new RectF();
scaledLocation.set(location);
canvas.drawRect(scaledLocation, paint);
result.setLocation(scaledLocation);
//draw out the recognition label and confidence
label_x = (scaledLocation.left + scaledLocation.right)/2;
label_y = scaledLocation.top + 16;
canvas.drawText(result.toString(), label_x, label_y, paint);
mappedRecognitions.add(result); ///do we need this??
}
}
return newResultsBitmap;
}
/**
* have Rectangle boundingBox represented in a scaled space of
* width x height we need to convert it to scaledBoundingBox rectangle in
* a space of scaled_width x scaled_height
* @param boundingBox
* @param width
* @param height
* @param scaled_width
* @param scaled_height
* @return scaledBoundingBox
*/
public RectF scaleBoundingBox( RectF boundingBox, int width, int height, int scaled_width, int scaled_height){
float widthScaleFactor = ((float) scaled_width)/width;
float heightScaleFactor = ((float) scaled_height)/height;
RectF scaledBoundingBox = new RectF(boundingBox.left*scaled_width, boundingBox.top*heightScaleFactor,
boundingBox.right*scaled_width, boundingBox.bottom*heightScaleFactor);
return scaledBoundingBox;
}
}
Now the Detecor class is used inside my MainActivity class
//declare Tensorflow objects
Detector tensorFlowDetector = new Detector();
//LATER ON IN CODE
public void onCameraViewStarted(int width, int height) {
//in case the TensorFlow option is chosen you must create instance of Detector
//depending on value of MODE variable in Detector class will load one of a few hard
// coded types of tensorflow models (ObjectDetectionAPIModel or Yolo or Multibox) and
// the associated asset files representing the pre-trained model file (.pb extension) and
// the class labels --objects we are detecting (*.txt) see Detector class for details
this.tensorFlowDetector.setupDetector(this);
}
//LATER ON WHEN YOU WANT TO USE THE DETECTOR --say in onCameraFrame()
/going to use created instance of Detector class to perform detection
//convert imageMat to a bitmap
Bitmap bitmap = Bitmap.createBitmap(imageMat.width(), imageMat.height(),Bitmap.Config.ARGB_8888);;
Utils.matToBitmap(imageMat,bitmap);
//now call detection on bitmap and it will return bitmap that has results drawn into it
// with bounding boxes around each object recognized > threshold for confidence
// along with the label
Bitmap resultsBitmap = this.tensorFlowDetector.processImage(bitmap);
//convert the bitmap back to Mat
Mat returnImageMat = new Mat();
Utils.bitmapToMat(resultsBitmap,returnImageMat);
return returnImageMat;
STEP 4: Make an assets file in your project and then Copy over ALL assets file from the zipped application assets directory
STEP 5: Copy over ALL the resources files from zipped application to your new applications resoruces directory
STEP 6: Change the Google Cloud VIsion key in the res/strings.xml to point to YOUR key you registered
with your google cloud vision account ----THAT IS IF YOU WANT THE Google cloud vision code to also work
*****but has nothing to do with the tensorflow stuff
STEP 7: Copy over the Manifest file from zipped directory to your new application
STEP 8: Run the code (see video above for results)
STEP 9: Now your ready to edit --add whatever you want --get rid of stuff--this App looks like part of Project 2
WARNING --- this code does not address issue explictly of dropped frames and relies on OpenCV to
handle this with its internal code.
WARNING 2 - whether you run this code OR the original cloned code that uses Android Camera rather than OPENCV --the code is NOT fast --- and some of you for some of your applications do not want to process video frames but, have the user take picture -stop the video frames process and then when
user prompts in some way continue ---it wont feel so bad then.