Speaker rate variation - Time Warping
|
What happens when people vary their rate of speech during a
phrase? How can a speaker verification system with a password of
"Project" accept the user when he says "Prrroooject"?
- Obviously, a simple linear squeezing of this longer password
will not match the key signal because the user slowed down the
first syllable while he kept a normal speed for the "ject" syllable.
- We need a way to non-linearly time-scale
the input signal to the key signal so that we can line up appropriate
sections of the signals (i.e. so we can compare "Prrrooo" to "Pro"
and "ject" to "ject").
- The solution to this problem is to use a technique known as
"Dynamic Time Warping" (DTW). This procedure computes a
non-linear mapping of one signal onto another by minimizing the
distances between the two.
|
Dynamic Time Warphing Algorihtm
|
Define the signal and difference between it a set "key"
signal (one with no variation in rate)
- In order to get an idea of how to minimize the distances
between two signals, let's go ahead and define two: K(n),
n = 1,2,...,N, and I(m), m = 1,2,...,M.
- We can develop a local distance matrix (LDM) which contains
the differences between each point of one signal and all
the points of the other signal. Basically, if n = 1,2,...,N
defines the columns of the matrix and m = 1,2,...,M defines
the rows, the values in the local distance matrix LDM(m,n)
would be the absolute value of (I(m) - K(n)).
LDM(m,n) = |I(m) - K(n) |
|
|
Goal
warping function (f) that minimizes the total
distance between the respective points of the two signals.
find f : K(i) ---> I(j)
such that minimize LDM(i,j) + surrounding values
of LDM(i,j)
|
|
Results
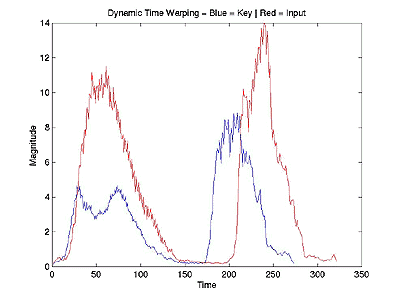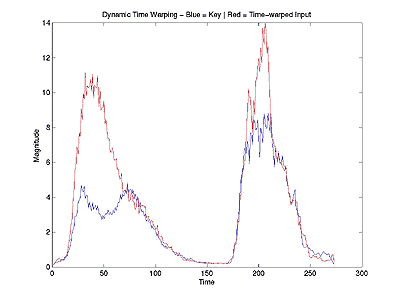
|
|
|