|
|
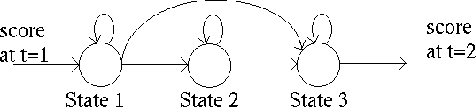
Hidden Markov Model (HMM)
|
The Hidden Markov Model is a finite set of states, each of which is associated with a (generally multidimensional) probability distribution. Transitions among the states are governed by a set of probabilities called transition probabilities. In a particular state an outcome or observation can be generated, according to the associated probability distribution. It is only the outcome, not the state visible to an external observer and therefore states are ``hidden'' to the outside; hence the name Hidden Markov Model.
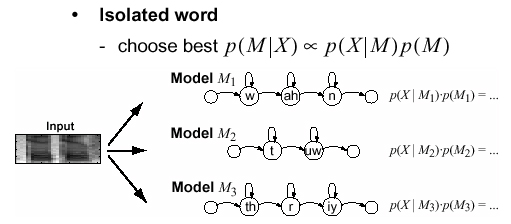
We can use HMM's to perform isolated word recognition
|
|
Can use HMMs for continuous speech recognition (not isolated words)
|